Nuestro lector de honor, Patxi (¡gracias!) nos enviaba esta consulta:
Mola la consultoría. Aquí va una pregunta: ¿llegarán nunca los ordenadores a intepretar imágenes? ¿y vídeo?
Yo me quedaré perplejo el día que a un ordenador le enseñes un video y te lo explique: «se ve un hombre corriendo sobre una playa y ahora rompe una ola…» o algo equivalente.
En realidad aquí se plantean muchas preguntas, así que voy a intentar ir por partes… Nos enfrentamos a un problema decisivo: no conocemos casi nada sobre el funcionamiendo del cerebro. El acto de interpretar es una actividad muy humana, en la medida que precisa de la subjetividad y de la experiencia… tendríamos que preguntarnos cómo percibimos nosotros al hombre que corre por la playa (magnífica excusa para plantar la foto :-P) y cómo sabemos que se trata de una persona… es mucho más complejo de lo que nos parece, porque estamos acostumbrados a interpretar constantemente.
 Así que, en cierto sentido, podemos responder que los ordenadores, tal como los conocemos, no serán capaces nunca de interpretar nada… la cuestión aquí es si realmente necesitamos que ellos interpreten de la misma forma en que lo hacemos nosotros… (pero no se desanimen, no todo es lo que parece)
Así que, en cierto sentido, podemos responder que los ordenadores, tal como los conocemos, no serán capaces nunca de interpretar nada… la cuestión aquí es si realmente necesitamos que ellos interpreten de la misma forma en que lo hacemos nosotros… (pero no se desanimen, no todo es lo que parece)
Los ordenadores sólo son capaces de resolver, en principio, los problemas para los cuales conocemos una serie de pasos que nos llevan a su resolución. Pues bien, no existe (no se conoce) una secuencia de este tipo que haga comprender a un computador que lo que se ve en el vídeo es un perro, o una persona, y que lo haga en general (es mucho más complejo que reconocer una letra)
La respuesta tenemos que buscarla en la Inteligencia Artificial. Hay que decir que la IA no es sólo un tema de películas de ciencia-ficción: funciona y sus resultados son prometedores, pero no es la gran revolución que se creía en un principio.
 Existe un tipo de computación basada en redes de neuronas. Una red de neuronas imita el funcionamiento de la mente humana: la idea es simular un montón de unidades independientes que pueden funcionar como pequeñas calculadoras, y que interactúan entre sí, tal y como lo hacen las neuronas en nuestro cerebro… puede parecer increíble, pero esto existe…
Existe un tipo de computación basada en redes de neuronas. Una red de neuronas imita el funcionamiento de la mente humana: la idea es simular un montón de unidades independientes que pueden funcionar como pequeñas calculadoras, y que interactúan entre sí, tal y como lo hacen las neuronas en nuestro cerebro… puede parecer increíble, pero esto existe…
Hace unos días veíamos cómo los ordenadores pueden reconocer texto y proponíamos una solución sencilla paso a paso. Ahora bien, en cuanto se distorsionaban las letras, el programa no era capaz de comprender nada… Sin embargo, existe una forma de aplicar redes de neuronas al reconocimiento de texto, utilizando [modo experto] una red de Hopfield, que es capaz de soportar una modificación de hasta el 25% de un caracter a reconocer… ¿Cómo lo hace?
Las redes de neuronas aprenden. La forma del aprendizaje es muy parecida a la nuestra: se le da a red un conjunto de datos inicial y se le pide que de un resultado, el que sea. Si es el que esperábamos, hemos terminado. Si no, ajustamos cómo se comunican las neuronas entre ellas y volvemos a probar… es como un entrenamiento. Parece complicado, y de hecho lo es. No obstante, funciona :-)
Sabiendo esto no puedo decir que un ordenador no vaya a ser capaz nunca de reconocer a un hombre corriendo en la playa, pero desde luego que si lo llega a hacer, será mediante un mecanismo de este tipo… (De hecho, nosotros reconocemos a otro humano caminando en la distancia bastándonos sólo en cinco o seis puntos que se mueven a cierto ritmo… es fascinante)
Ahora mismo podríamos tomar una red de neuronas y entrenarla para que reconociera un hombre corriendo (esto existe, de hecho, en algunos sistemas de seguridad, aunque es bastante primitivo). También podríamos lograr que reconociera en un vídeo como rompe una ola (dosis extra de dificultad). Los límites de este tipo de estructuras no están nada claros, para bien o para mal.
 El problema surge al generalizar: el querer una red que estudie un vídeo o una imagen y que identifique lo que sea, cualquier cosa, un perro, un gato, un calamar gigante o un humano… yo me atrevería a decir que no parece posible, salvo que el sistema aprenda todos los objetos que pueden aparecer: sus formas, su comportamiento y sus variantes… lo cual implicaría un entrenamiento largo, como el que podamos tener las personas… pero no veo por qué no podría hacerse.
El problema surge al generalizar: el querer una red que estudie un vídeo o una imagen y que identifique lo que sea, cualquier cosa, un perro, un gato, un calamar gigante o un humano… yo me atrevería a decir que no parece posible, salvo que el sistema aprenda todos los objetos que pueden aparecer: sus formas, su comportamiento y sus variantes… lo cual implicaría un entrenamiento largo, como el que podamos tener las personas… pero no veo por qué no podría hacerse.
En conclusión, considero que sí es posible que los ordenadores reconozcan fenómenos concretos en imágenes o en vídeo. Serán necesarias, eso sí, estructuras más avanzadas que la computación tradicional, y que estas estructuras hayan sido entrenadas con cierto volumen de datos. No obstante, será muy complicado que reconozcan todas las situaciones posibles sin que hayan sido previstas, tal y como hacemos nosotros, y en grados variables de detalle… Pero sin duda, más tarde o más temprano, la respuesta a la pregunta de Patxi será un S?.
Cuando aparecieron los primeros ordenadores, hubo quien dijo que jamás tendrían éxito por el increíble coste que tendrían… es mejor tener la mente abierta, uno siempre se lleva sorpresas ;-)
PD: Perdón por el post kilométrico, pero el tema lo merece…










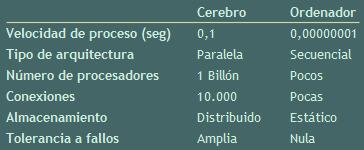
 Sintiéndolo mucho por los ordenadores, el más estúpido de los humanos es más inteligente que el mejor computador. Aunque no estemos siendo muy justos. Por ejemplo, somos mucho mejores que las máquinas realizando trabajos abstractos, como reconocer patrones y todos los que se nos plantan en los tests de inteligencia.
Sintiéndolo mucho por los ordenadores, el más estúpido de los humanos es más inteligente que el mejor computador. Aunque no estemos siendo muy justos. Por ejemplo, somos mucho mejores que las máquinas realizando trabajos abstractos, como reconocer patrones y todos los que se nos plantan en los tests de inteligencia.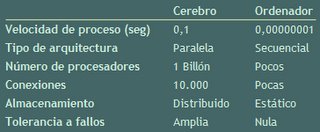

 ¿Qué es una cookie? Una «cookie» (galleta o tarta en inglés). [Actualización:
¿Qué es una cookie? Una «cookie» (galleta o tarta en inglés). [Actualización: 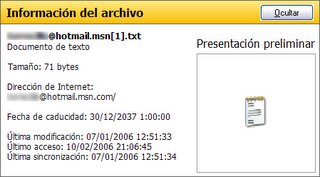

{kind=link}
{kind=link}